Risk classification refers to the use of observable characteristics, such as gender, race, age, and behavior, to price or structure insurance policies. Risk classification potentially has undesirable consequences, including adverse effects on distributional equity. In dynamic settings, risk classification can also increase classification risk, which refers to the risk that an individual faces of being reclassified into a higher-cost class at a later date.
A perfect risk classification system should, using actuarial rules and principles, generate an insurance premium that reflects the expected cost associated with a given risk. Two clients with the same risk level should pay the same, actuarially fair premium. This is known as the financial equity criteria. In health insurance, premiums are most commonly determined by age, sex, and smoking behavior. Current medical conditions (high cholesterol, diabetes, etc.) and medical histories of older clients are often added as criteria because they can affect the medical expenses covered by the insurance plan. Information on lifestyle, diet, and exercise can also be considered.
Market forces push competitive insurers toward employing risk classification whenever it is legal (and permissible according to social norms) to do so. For example, age is an easily observable characteristic that is often correlated with expected health care expenditures. If insurers do not price their insurance products on the basis of age, they will find that, on average, selling policies to the lower-risk young is more profitable than selling policies to the higher-risk old. Individual firms will therefore have an incentive to cream skim – to offer a lower-priced insurance product only to the young and thereby to attract only the most profitable risks.
Selection and pricing activity based on individual characteristics is subject to concerns about social fairness (or equity) and potential discrimination. This is particularly true in the medical and disability insurance markets. Policy makers who dislike the consequences of risk classification may therefore find it desirable to use regulatory restrictions to limit its use. Indeed, risk classification is restricted or banned outright in various markets, for example, via community rating laws that require insurers to offer all individuals in a given community the same policies at the same premiums, as the compulsory public health system in Canada and several US states.
The policy decision to restrict the use of risk classification often involves a trade-off between financial and social equity. This trade-off is policy relevant because departures from financial equity can lead directly to inefficient insurance provision. For example, risk pooling arising from legal restrictions on risk classification variables may lead to a situation in which lower-risk individuals are faced with higher premiums than those corresponding to their true risk, whereas higher-risk individuals pay lower premiums. Low-risk individuals may leave the pool, driving premiums higher and causing even more individuals to leave the pool. This inefficient market unraveling is known as an adverse selection death spiral.
Understanding the cost and benefits of risk classification more generally is challenging for at least two reasons. First, there are a number of interrelated and overlapping effects of risk classification that are difficult to disentangle. Second, the relative importance of these various effects depends strongly on the institutional details of the insurance market. In some markets, permitting risk classification facilitates efficient insurance provision without compromising concerns about equity. In some others, banning risk classification has beneficial equity effects without imposing any efficiency costs. In others, the decision to ban risk classification involves a nontrivial trade-off between equity and efficiency goals.
This article provides a simple framework for identifying the types of markets in which these three cases arise. One of the key determinants is the presence or absence of residual asymmetric information in the market. This article reviews empirical tests for asymmetric information in health insurance markets.
Potential Welfare Effects Of Risk Classification
Public policy typically involves trade-offs between equity and efficiency. Public policy regarding risk classification in insurance markets is no exception. It is further complicated by the presence of several conceptually distinct but overlapping notions of equity and efficiency.
Equity
There are at least four potential notions of equity in the risk-classification context: horizontal equity, financial equity, group equity, and distributional equity.
Horizontal equity refers to the idea that any two individuals facing identical insurable risks should be treated identically: they should, for example, have access to the same policies and at the same prices. Group equity, however, refers to the idea that each identifiably distinct group (e.g., males, 25-year-olds) should not, as a group, be required to cross subsidize other groups. A desire for this type of equity is sometimes referred to as subsidy aversion. Financial equity is a special case of group equity in which there is no heterogeneity within the group.
The goals of horizontal and group equity are frequently in tension with each other. By way of illustration, consider a population consisting of otherwise homogenous 30-year-old men and women seeking individual health insurance policies. Suppose that there is only one type of policy available; the only question is, what price individuals will be charged for it? Suppose further that the expected cost to an insurer of providing coverage to a woman is higher, on average, than the cost of providing coverage to a man.
If insurers risk-classify using gender, then women in the population will face higher insurance prices. Group equity will be satisfied at the level of gender, as each gender will be charged an appropriate premium. Insofar as not all women in the group are identical, however, financial equity will not be satisfied. Moreover, some women, perhaps those in good health with no interest in bearing children, are likely to have lower than average expected costs and, similarly, some men are likely to have higher than average expected costs. So it is likely that there are some men and some women in the population with exactly the same expected costs to insurers. Because insurers are risk-classifying by gender, these two identical risks will be charged different premiums for identical coverage. This violates horizontal equity. On the other hand if insurers do not risk-classify by gender, then horizontal equity will be trivially satisfied. Group equity will be violated, however, because the lower-on-average-risk men will be charged the same as women, men as a group will effectively be cross-subsidizing women as a group.
Group and financial equity are founded on an actuarial notion of fairness: What is fair to an individual or group is that they be charged prices in relation to their true cost to an insurer. Like horizontal equity, distributional equity is a nonactuarial notion. It refers to the idea that, at least in some circumstances, two individuals should be charged the same price in spite of the fact that they, or groups they are members of, face different risks. Bans on risk classification on the basis of genetic conditions such as Huntington’s disease, or on the basis of preexisting conditions more generally, are primarily motivated by a concern for distributional equity.
Distributional equity also encompasses attempts to use policy for the explicit purpose of redistributing from a historically advantaged class (e.g., males) to a historically disadvantaged class (e.g., females). This is distinct from concerns for actuarial group equity – i.e., that one group should not subsidize another in an actuarial sense. Because riskiness rather than group membership is the more fundamental characteristic vis-a-vis insurance provision, it is not obvious why providing distinct groups of heterogeneous risks actuarially equally would be a desirable policy goal. This article therefore focuses primarily on horizontal, financial, and distributional equity.
Efficiency
There are at least two distinct notions of efficiency that are relevant in the risk-classification context: interim efficiency and ex-ante efficiency. There are two distinct types of interim efficiency: the efficiency of outcomes and the efficiency of institutions.
Insurance outcomes in market A are said to be more interim efficient (or interim Pareto efficient) than insurance outcomes in market B when every individual is at least as happy with the insurance policy they would get in market A as with the insurance policy they would get in market B, and someone is strictly happier. Equivalently, market B’s outcomes are interim inefficient if nobody would object to replacing the market with market A’s outcomes, and at least somebody would strictly prefer the switch.
The notion of interim efficiency of institutions is applied when there is a range of possible insurance outcomes consistent with different policy institutions. The range of possible outcomes consistent with a policy regime in which risk classification is legal, for example, may depend on the extent to which the government also imposes taxes on the contracts sold to different risk classes. Similarly, there may be a range of insurance outcomes consistent with a regime in which risk classification is banned. Saying that the institution of legal risk classification is interim efficient means that for every potential banned classification outcome, there is some legal classification outcome that makes every individual at least as happy (and some strictly happier).
Interim efficiency involves evaluating insurance markets from the point of view of individuals who know their type (which could include intrinsic riskiness or tastes) and risk class. Because there are typically many types and classes within a given population, there will typically be many different possible insurance outcomes which cannot be compared on interim efficiency grounds, as some individuals would be better-off with one of these outcomes, and other individuals would be better-off with another.
In contrast, ex-ante efficiency evaluates efficiency from the point of view of a representative individual behind a veil of ignorance about their risk type or class. Insurance outcomes in market A are thus said to be more ex-ante efficient than insurance outcomes in market B if a hypothetical individual who did not yet know what risk type or class they will belong to would prefer the market A outcomes.
The notions of distributional equity and ex-ante efficiency are closely related. One might reasonably use the notion of distributional equity to argue that individuals with the gene for Huntington’s disease should be able to purchase insurance covering the costs associated with its treatment for the same premium as someone without the gene. One basic argument is that it would be unfair to charge an individual for something entirely out of their control. Alternatively, one could make the same arguments on the grounds of ex-ante efficiency: A risk-averse representative individual behind the veil of ignorance, who did not yet know whether or not they would be born with the gene, would strictly prefer to be born into a world in which premiums do not depend on the presence of the gene.
Distributional equity can potentially be invoked for other unrelated reasons, but this article focuses on the particular distributional equity concerns arising from the point of view of a representative, risk-averse individual behind a veil of ignorance about their type and class. In other words, it regards as beneficial policies which redistribute toward risk types that are relatively disadvantaged from an ex-ante point of view.
Another way of framing the desire for, for example, geneindependent pricing is in terms of a desire for insurance against classification risk. Because individuals are either born with the Huntington’s disease or not, individuals cannot directly insure themselves against the risk of having the gene and being in a bad risk class. Preventing insurers from genetic discrimination is potentially desirable insofar as it effectively provides otherwise unavailable insurance against this classification risk.
A similar argument potentially applies more generally to bans on risk classification on the basis of preexisting conditions like cancer or diabetes. The primary conceptual distinction is that one could, in principle, have insured oneself against such classification risk by purchasing a long-term, or guaranteed renewable contract before the condition developed. Insofar as the market for long-term contracts or other forms of insurance against classification risk functions poorly, however, restricting risk classification has potentially beneficial distributional equity effects insofar as it reduces classification risk.
It is important to note that interim inefficiency of outcomes implies ex-ante inefficiency as well. If outcomes in market A are better than market B outcomes at the interim stage for each type, then the representative agent behind the veil of ignorance will necessarily prefer market A. Interim inefficiency in the institutional sense implies ex-ante inefficiency in a somewhat more subtle sense. As a stand-alone policy, for example, a ban on risk classification might reduce interim efficiency (in the institutional sense) yet raise ex-ante efficiency through beneficial distributional equity effects. Nevertheless, interim inefficiency in the institutional sense implies the existence of some alternative intervention, such as government-coordinated risk adjustments, that is even better than a ban from an ex-ante perspective.
The Equity And Efficiency Trade-Offs Of Risk Classification
Risk classification will typically have implications for both efficiency and equity. The particular trade-offs between efficiency and equity implied by the decision to allow or ban risk classification in insurance markets are context-dependent. Figure 1 provides a simple framework for sorting these contexts.
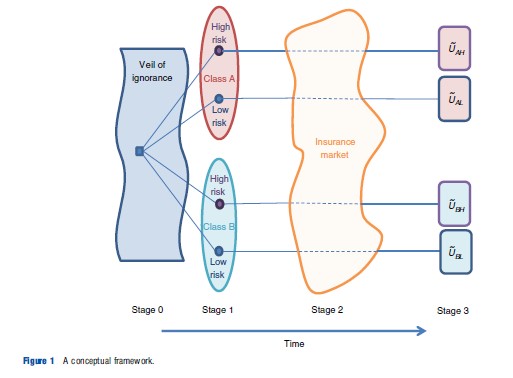
Figure 1 depicts the timing of an abstract insurance market. At stage 0, a notional representative individual contemplates the future from behind a veil of ignorance. At stage 1, individuals are born and learn both their true risk type and their class. The diagram depicts a case with two risk types, high and low risks, and two classes, labeled A and B, which might represent male and female, white and nonwhite, or Huntington’s positive and negative, for example.
At stage 2, individuals enter an insurance market and potentially purchase insurance. At stage 3, the health outcomes are realized, and individuals with insurance receive their coverage and choose treatment levels. These outcomes result in a random utility, or well-being, level denoted by Uij that will potentially depend on risk type j and class i.
This framework can be used to explore the consequences of risk classification in a variety of situations. For example, if classes A and B are 30-year-old females and males, respectively, then it encompasses the example above illustrating the trade-off between individual and group equity when there is a lower but nonzero fraction of high-risk types within class A and a lower but nonzero fraction of low-risk types within class B. To capture a situation like classification based on the presence of the Huntington’s gene in which class is perfectly predictive of risk type, one would simply take the fractions of the high-risk types within classes A and B to be one and zero, respectively.
The framework is best suited for analyzing insurance decisions that take place at one moment in time. It is less well suited to addressing fundamentally dynamic issues, such as the implications of risk classification based on preexisting conditions like diabetes or heart disease. It can be adapted to this application if insurance is sold on an annual basis with no long-term contracting, however. Similarly, it can be fruitfully applied to analyze the implications of age-based risk classification in some contexts.
When this simple framework is applicable, the qualitative implications of risk classification hinge on three basic questions.
Question 1: Is Risk Classification Perfect Or Imperfect?
In some cases, as with the BRCA1/2 breast cancer gene, class is only imperfectly correlated with risk: There may be women without the gene who still face a high risk of breast cancer. In other cases, such as the gene for Huntington’s disease, class is closer to perfectly predictive of risk type, and all members of either class will have the same risk type. It may then be said that risk classification is perfect.
Whether or not risk classification is perfect is important for two reasons. First, when risk classification is perfect, classes are pools of individuals who are perfectly homogenous from the point of view of health risk. The tension between horizontal and group equity therefore disappears. Second, when risk classification is imperfect, insurers who employ risk classification still face heterogeneity of risks within each class. Employing risk classification therefore reduces, but does not eliminate informational asymmetries. This is important because, in the face of informational asymmetries, insurers may find it useful to employ indirect mechanisms to induce self-sorting of different risks. This is known as screening. Screening can have important implications for efficiency and equity.
Question 2: Are Policies Uniform Or Not?
Screening refers to the deliberate attempt to induce self-sorting of individuals through contract design. In the canonical example of screening, insurers offer two types of policies: An expensive comprehensive policy and a less expensive and less comprehensive policy, such as a catastrophic coverage policy with a very high deductible. Individuals who know themselves to be in good health are more likely to find the latter an appealing option, so individuals will be induced to self-sort by riskiness into distinct policies.
Screening relies on insurers’ ability to tailor menus of significantly different policy options: it is predicated on nonuniform policies. If regulatory restrictions circumscribe insurers’ ability to design such menus, for example, through coverage mandates that require all insurance policies to cover a certain same set of conditions, then screening will be curtailed or eliminated.
To see why the uniformity or nonuniformity of policies can have important implications for the equity and efficiency effects of banning risk classification, consider the effects of banning gender-based risk classification. If insurers find it much more costly to provide health care to women than to men then, absent any coverage mandates, it could potentially circumvent the ban by offering two policies: An expensive and comprehensive policy, and a less expensive one providing comprehensive coverage for everything except childbirth, breast cancer, gynecological examinations, and other genderspecific health care needs. Women faced with such a menu would find it worthwhile to pay the higher premium for coverage of their needs, and men would not. In this case, the insurer would effectively circumvent the risk classification ban, which would consequently have neither efficiency nor equity effects. In contrast, a ban imposed under coverage mandateinduced policy uniformity would likely have welfare effects.
Question 3: Are Insurance Purchases Mandated Or Not?
In markets without purchase mandates, individuals who perceive themselves to have the greatest need for insurance, and hence the highest expected costs to insurers, will be differentially more likely to purchase coverage, whereas lower-risk individuals are differentially likely to opt out of buying coverage at all. In this case, the pool of insured individuals is said to be adversely selected relative to the population. An adversely selected risk pool requires higher premiums for firms to break even. In the most severe cases, adverse selection can completely destroy a market via an adverse selection death spiral.
Because purchase mandates and risk classification are two different ways to mitigate adverse selection, the presence or absence of a purchase mandate is crucial for analyzing the equity and efficiency implications of risk classification.
A Quick-And-Dirty Guide To The Equity–Efficiency Trade-Offs
The eight distinct answers to the set of three questions above describe eight conceptually distinct institutional contexts. In practice, however, purchase mandates are typically coupled with minimum coverage mandates that limit the degree of policy differentiation: otherwise, individuals could fulfill the mandate by purchasing a low-priced contract providing essentially zero coverage. Therefore the two regimes with mandated purchases and differentiated products are not considered.
Table 1 provides a quick reference guide to the efficiency and equity effects of risk classification in the six remaining institutional contexts. It focuses on interim efficiency and horizontal, financial, and distributional equity, with beneficial distributional equity effects interpreted as those which would be desirable from the point of view of the veiled representative individual at stage 0 in Figure 1.
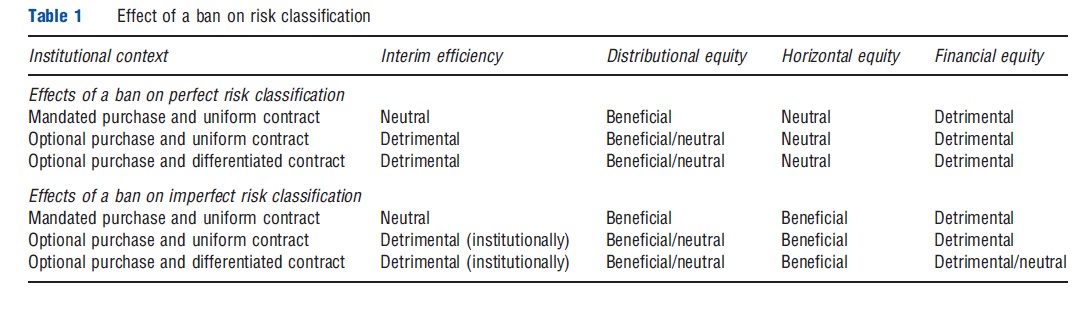
Consider first environments with a purchase mandate and a uniform contract. Bans on risk classification are the least likely to be controversial in these environments, because they improve distributional equity in a horizontally equitable way without harming interim efficiency. This is because only premiums, not insurance coverage, are affected by risk classification, and banning risk classification beneficially (from an ex-ante perspective) redistributes from individuals who were born into the fortunate group with fewer low risks to those who were unlucky enough to be born into the higher-risk group.
When risk classification is imperfect, but purchases of a uniform contract are still mandatory, such a ban also has a beneficial impact on horizontal equity, because it prevents individuals with the same true risk from being charged different premiums by virtue of the group to which they happen to belong. The primary objections to banning risk classification in mandatory-purchase uniform-contract contexts are likely to stem from financial equity effects; some might feel strongly that individuals should not be forced to cross subsidize others. This objection is likely to be particularly germane for risk classification based on preexisting and preventable conditions, but it may be present more broadly.
In an optional-purchase institutional context, banning risk classification may additionally induce efficiency reducing adverse selection effects. Suppose, for example, that group A consists of people with an expensive-to-treat preexisting condition and group B consists of healthy individuals. With legal risk classification, the market will segment and group B individuals will pay lower premiums. One possibility, if risk classification is banned, is that all individuals will continue to purchase insurance at some intermediate premium. In this case, the welfare effects are exactly as with a mandate. The other possibility is that the market will suffer from a death spiral: Group B individuals will find insurance too expensive at the new premium and will leave the market. Premiums for the group A individuals will then rise to the same as they were before the ban was imposed. In this case, the risk classification ban will be purely efficiency reducing. It will have no beneficial equity effects at all.
Similar adverse selection-driven negative efficiency effects arise with a richer and more realistic set of individual risk types. If the adverse selection is mild, so that only a few of the lowest-risk types are driven from the market by a ban in risk classification, then policy makers will face a genuine trade-off between beneficial distributional equity effects of uniform pricing and the efficiency costs of adverse selection. With sufficiently severe adverse selection, the uniform pricing will have at most mild distributional equity benefits, and ex-ante efficiency will be reduced. If a policy maker wanted to ban risk classification and believed that the adverse selection problem was likely to be severe, introducing a purchase mandate would therefore be essential. This was the primary motivation for policy makers to include a coverage mandate in the Patient Protection and Affordable Care Act passed by the US Congress and signed into law by President Barack Obama in 2010.
A similar trade-off between interim efficiency and distributional equity applies if risk classification is imperfect, but the interim efficiency effects of a ban are detrimental in the institutional sense rather than in the outcome-based sense. In particular, one can show that the outcome with banned risk classification can always be Pareto improved on with legal risk classification and some appropriate risk adjustments, for example, through government-administered transfers across insurers serving different risk classes.
The detrimental interim efficiency effects of banning perfect risk classification are also similar when contracts are differentiated and insurance is not mandated (bottom rows). The mechanism is somewhat different, however: Low-risk individuals will be screened – induced to self-select – into a high deductible policy providing worse coverage rather than being adversely selected out of the market entirely. There is some disagreement among economists about the precise nature of screening in insurance markets; some widely used models of insurance markets predict the same outcomes with and without risk classification bans, and, consequently, no distributional equity effects. Others predict the potential for beneficial distributional equity effects via pooling of different risk types or cross-subsidies across distinct contracts.
It is clear that even in the simple analytical framework depicted in Figure 1, evaluating the welfare consequences of risk classification is nontrivial and highly context-dependent. Of the three central questions identified above as being useful for understanding these welfare effects, the latter two are observable policy questions. The first question is an empirical one. It can be understood as a question about the presence or absence of asymmetric information: Risk classification is imperfect precisely when there is unused information about risk within a risk class. In these cases, incentive contracting – designing contracts to mitigate the imperfections of the risk classification technology – can play an important role. Screening is the type of incentive contracting that is particularly important when the relevant asymmetric information within a risk class is of the adverse selection type, as has largely been assumed up to this point, but other types are potentially important with other types of informational asymmetries. In part because of its central importance for the welfare analysis of risk classification, the presence or absence of informational asymmetries has been the subject of much recent empirical work.
Risk Classification And Residual Asymmetric Information In Health Insurance Markets
Perfect risk classification should separate individual risks and generate different actuarial insurance premiums that reflect these risks. With actuarial premiums, full insurance should be the optimal contract, and there should not be any correlation between insurance coverage and individual risk. But in the real life of health insurance contracting, there are numerous reasons for imperfections in risk classification. Particularly important among these is the possibility of residual asymmetric information within a given risk class. Recent empirical work has therefore focused on searching for evidence for presence and extent of this sort of residual asymmetric information.
General Tests For Residual Asymmetric Information
Information problems are common in insurance markets. Usually, the insured are better informed about their own characteristics or actions than are their insurers. The two best-known information problems discussed in the economics literature are adverse selection, discussed above, and moral hazard, where insurance leads individuals to take unobserved actions either before (ex-ante moral hazard) or after (ex-post moral hazard) the realization of health outcomes that raise the costs borne by the insurer. Asymmetric learning over time is a third information problem. Because similar empirical patterns are predicted by these three problems, empirical work on information problems is challenging.
Empirical work has three sequential goals. The first is to determine whether information problems exist, and, if so, how severe they are. The second is to identify which information problem or problems are present when the first test rejects the null hypothesis that there is no information problem. This is important for an insurer because it must implement the appropriate instruments to improve resource allocation. A fixed deductible, for example, efficiently reduces ex-ante moral hazard, but not necessarily ex-post moral hazard. A high deductible can even have an adverse effect and encourage accident cost building.
The third goal is to find ways to improve the contracts and reduce the negative impact of asymmetric information on resource allocation. These resource allocation objectives must take into account other issues, such as risk aversion, equity, and accessibility of services. This last issue is particularly important in health care markets. A decrease in insurance coverage may reduce ex-ante moral hazard because it exposes the insured person to risk, but it also significantly reduces accessibility to health services for sick people who are not responsible for their condition. Although the third goal is ultimately the most important, this article focuses on the first two goals, which have been convincingly tackled in the literature only recently.
Well-constructed theoretical models with carefully established theoretical predictions are essential for achieving these goals. Many theoretical contributions were published in the 1970s which appealed to asymmetric information to account for stylized facts observed in insurance markets. Not all of these accounts were readily adapted to formal tests of information asymmetries, however. For example, partial insurance, such as deductible and co-insurance contracts, can be justified by either moral hazard or adverse selection, but proportional administrative costs can also justify it. So the mere fact that these are common features of real-world insurance policies does not imply the presence of asymmetric information.
The following simple question has motivated most recent empirical work toward the first goal: Do insurers that apply risk classification techniques based on observable characteristics in their underwriting policies also find it useful to employ contract design to further separate risk types within the risk class? In static or one-period contracts, the answer is no unless there is residual asymmetric information within the risk classes. (The reality is, of course, much more complicated because contract duration between the parties can cover many periods, and over time the true risks may become known to both parties.) Finding a residual correlation between chosen insurance coverage and risk within risk classes is therefore a tell-tale sign of asymmetric information. Tests for such a correlation have been the centerpiece of the empirical literature on information problems in insurance markets.
Econometricians analyze two types of information when studying insurers’ data. The first type contains variables that are observable by both parties to the insurance contract. Risk classification variables are one example. Econometricians/insurers combine these variables to create risk classes when estimating accident distributions. They can be used to make estimates conditional on the risk classes or inside the risk classes. The second type is related to what is not observed by the insurer (or the econometrician) during contract negotiations or selections, but can explain the insured’s choice of contracts or actions. A typical empirical study looks for the conditional residual presence of asymmetric information in an insurer’s portfolio by testing for a correlation between the contract coverage and the realization of the risk variable during a contract period. Different parametric and nonparametric tests have been proposed in the literature.
Finding a positive correlation between insurance coverage and risk is a necessary condition for the presence of asymmetric residual information, but it does not shed light on the nature of the information problem. In insurance markets, the distinction between moral hazard and adverse selection boils down to a question of causality. Under moral hazard, the structure of an insurance contract drives the unobserved actions, and hence the riskiness, of the insured. For example, a generous health insurance plan can reduce the incentives for prevention and increase the risk of becoming sick. Under adverse selection, the predetermined riskiness of an individual drives their contract choices: Higher-risk individuals will tend to choose policies providing better coverage. The correlation between insurance coverage and the level of risk is positive in both cases, but the directions of causality in the two cases are exactly opposite.
To separate moral hazard from adverse selection, econometricians need a supplementary step. In insurance markets, dynamic data are often available. Time adds an additional degree of freedom to test for asymmetric information, particularly in the presence of experience rating – whereby future premiums depend on past accident history. Experience rating works at two levels in insurance. Past accidents implicitly reflect unobservable characteristics of the insured (adverse selection) and introduce additional incentives for prevention (moral hazard). Experience rating can therefore directly mitigate problems of adverse selection and moral hazard, which often hinder risk allocation in the insurance market.
The failure to detect residual asymmetric information, and more specifically, moral hazard and adverse selection in insurance data, is often due to the failure of previous econometric approaches to model the dynamic relationship between contract choices and claims adequately and simultaneously when looking at experience rating. Intuitively, because there are at least two potential information problems in the data, an additional relationship to the correlation between risk and insurance coverage is necessary to test for the causality between risk and insurance coverage.
Testing For Asymmetric Information In The Health Insurance Market
Many reviews of empirical studies in different insurance markets have been published, including health insurance and long-term care insurance. It is observed that the coverage–risk correlation is particular to each market. Accordingly, the presence of a significant coverage–risk correlation has different meanings in different markets, and even in different risk pools in a given market, depending on the type of the insured service, the participants’ characteristics, institutional factors, and regulation. This means that when testing for the presence of residual asymmetric information, one must control for these factors as well. Up to now the empirical coverage–risk correlation findings have been equivocal. What characteristics and factors explain the absence of robust coverage–risk correlations in health insurance markets?
Long-term care market and the health care market are analyzed separately, notably because long-term care insurance effectively combines both health insurance and longevity insurance (annuities). It is well documented that private long-term care insurance is very expensive in the US and therefore not very popular. Less than 5% of the elderly participate in this market. Is it due to adverse selection? Those who purchase this coverage do not seem to represent higher risks than the average population. This negative result is explained by a combination of two opposite effects: A pure risk effect and a risk aversion effect. For a given risk aversion, higher-risk individuals buy more insurance under asymmetric information, as do more risk-averse individuals (who are assumed to engage in more prevention to reduce their risk). The net effect on the correlation between risk and coverage is not significant because both high-risk and low-risk individuals buy this insurance. However, it is not evident that more risk-averse individuals put forth more effort. Consequently, the absence of correlation may be explained by factors other than risk aversion.
Many empirical studies in the literature find a positive correlation between poor health condition and generous coverage, whereas other studies do not find this correlation. Some do not reject asymmetric information in the medical insurance market, but do not find evidence of adverse selection. Their results are even consistent with multidimensional private information along with advantageous selection. Indeed, some obtain a negative correlation between risk and insurance coverage. The significant sources of advantageous selection are income, education, longevity expectations, financial planning horizons, and most importantly, cognitive ability.
Other studies offer detailed analyses of health insurance plans. For example, it is shown that when the employer increased the average participation cost of the most generous plan for the policyholders, regardless of the risk they represented, the best risks in the pool with lower medical expenses left this plan for a less generous one with a lower premium. The new insurance pricing clearly generated adverse selection. Even if the age of the insured were observable, the insurance provider did not use this information, and the younger participants abandoned the more generous plan. This is a case in which the absence of a proper risk classification yielded severe adverse selection. This type of constraint, wherein risk classification variables are not used, is often observed in the health care market where the trade-off between efficiency and distributional equity matters.
One potential reason for not observing a significant correlation between coverage and risk is the absence of insured private information on the insured’s health status. Young individuals who may not have experienced any health problems may think they belong to the low-risk group. The statistical test should be done within these risk classes, even if the employer does not use age as a risk classification variable. Another reason for the lack of risk–coverage correlation, which may also apply to health insurance, is policyholders’ failure to use their private information when selecting insurance policies. It has been found, for example, that the demand for life insurance is not sensitive to insurance price and risk.
It has also been documented that insurance consumption depends on institutions. Moreover, risk classification in the health care market is heavily regulated in many countries. Therefore, the empirical predictions based on the implicit assumption of competitive markets may not be appropriate for many markets, including health insurance. For further discussion on particularities other than efficient risk classification that may generate an absence of correlation between insurance coverage and risk, see the references in reading.
Conclusion
This article has discussed the complex welfare effects of risk classification in health insurance. The policy decision to permit or ban risk classification may have consequences for efficiency, for equity, or for both. The various relevant notions of efficiency and equity appropriate in health insurance context were reviewed and trade-offs that are likely to arise in various institutional contexts were qualitatively characterized. A key question for this characterization is whether or not there is (or would be) within-class residual asymmetric information when insurers employ risk classification based on observable characteristics. The extensive and growing empirical works on this question were discussed. There remains substantial scope for future empirical work directed toward quantifying the equity–efficiency trade-offs of risk classification.
References:
- Buchmueller, T. and DiNardo, J. (2002). Did community rating induce an adverse selection death spiral? Evidence from New York, Pennsylvania, and Connecticut. American Economic Review 92, 280–294.
- Chiappori, P. A. and Salanie´, B. (2013). Asymmetric information in insurance markets: Predictions and tests. In Dionne, G. (ed.) Handbook of insurance, 2nd ed. Boston: Springer.
- Cohen, A. and Siegelman, P. (2010). Testing for adverse selection in insurance markets. Journal of Risk and Insurance 77, 39–84.
- Crocker, K. J. and Snow, A. (1986). The efficiency effects of categorical discrimination in the insurance industry. Journal of Political Economy 94, 321–344.
- Crocker, K. J. and Snow, A. (2013). The theory of risk classification. In Dionne (ed.) Handbook of insurance, 2nd ed. Boston: Springer.
- Cutler, D. M. and Zeckhauser, R. J. (2000). The anatomy of health insurance. In Culyer, A. J. and Newhouse, J. P. (eds.) Handbook of health economics, 1, pp. 563–643. Amsterdam: Elsevier Science.
- Dionne, G., Fombaron, N. and Doherty, N. A. (2013). Adverse selection in insurance contracting. In Dionne, G. (ed.) Handbook of insurance, 2nd ed. Boston: Springer.
- Dionne, G. and Rothschild C. G. (2012). Risk classification in insurance contracting, Working paper, Canada Research in Risk Management, HECMontre´al, 50 pages, SSRN 1958176.
- Harrington, S. (2010). U.S. health-care reform: The patient protection and affordable care act. Journal of Risk and Insurance 77(3), 703–708.
- Hoy, M. and Polborn, M. (2000). The value of genetic information in the life insurance market. Journal of Public Economics 78, 235–252.
- Rothschild, M. and Stiglitz, J. (1976). Equilibrium in competitive insurance markets: An essay on the economics of imperfect information. Quarterly Journal of Economics 90, 629–649.
- Thiery, Y. and Van Shoubroeck, C. (2006). Fairness and equality in insurance classification. Geneva Papers on Risk and Insurance: Issues and Practice 31, 190–211.