Introduction
The flow of new medical technologies is a response to several factors including an ageing population, changes in environmental conditions creating new epidemiological profiles and scientific development. This impacts on health care systems which, to satisfy increased demand for medical technologies, are faced with the need to increase expenditure on healthcare or to disinvest in other services to release resources. Regardless of the type of healthcare system, the problem of deciding which new technologies to fund is unavoidable. As policy makers are increasingly held accountable for these decisions, many are adopting explicit and evidence-based approaches to the allocation of limited resources. This needs, at the very least, information about which interventions work and the value of such technologies.
In a growing proportion of jurisdictions ‘value’ is defined in terms of cost-effectiveness, where the incremental cost of a new technology per additional health outcome relative to alternative interventions for a given patient group is assessed. This incremental cost-effectiveness ratio is then compared with a maximum (or threshold) value of a unit of health gain which is based either on an estimate of the health forgone as a result of displacing existing services to fund the new technology, administrative rule of thumb or an estimate of society’s willingness to forgo consumption in exchange for health improvement. Both effectiveness and cost-effectiveness are usually considered as average estimates relating to a target population. This approach has been largely justified by the fact that it is impossible to observe the effect of alternative treatments in the same individual at the same time, a problem known as the ‘fundamental problem of causal inference’. Average treatment effects derived from randomized controlled clinical trials are unbiased estimates when the groups being compared have, on average, similar characteristics, so that the differences in the outcomes are attributable to the treatment received by patients in each group. This causal statement is possible because randomization is expected to balance observed or unobserved confounding factors.
Although the focus on average treatment effects is widespread, this is essentially pragmatic given the challenges in estimating individual treatment effects. The promise of genetic testing is that patient management can more appropriately be tailored to the characteristics of the individual – a technological approach to understanding between-patient heterogeneity in treatment effects. However, in jurisdictions using formal cost-effectiveness analysis to inform resource allocation decisions, as well as those that are unwilling or unable to consider costs explicitly (e.g., comparative effectiveness research in the US), there is a recognized need to understand heterogeneity using existing data on predictors of patients’ outcomes following alternative interventions. The focus on the average patient leads to dichotomous decisions – accept or reject a given intervention for all patients in a given population. In contrast, understanding of heterogeneity in costs, effects and cost-effectiveness between patients within the population facilitates decisions which may guide the use of the intervention toward those patients in whom it is (cost-) effective. This targeted, rather than general, funding of interventions frees-up resources for more (cost-) effective alternatives, leading to an improvement in the overall population health from a given budget allocation. In principal, a full understanding of heterogeneity allows decisions to reflect the characteristics of the individual patient, so the gains from reflecting heterogeneity are maximized.
Interest in heterogeneity for decision-making takes various forms. From a biomedical perspective, reflecting heterogeneity in decisions has been promoted as a means of achieving personalized medicine, which requires the identification of measurable parameters (e.g., based on molecular biomarkers) that allow doctors to prescribe treatments according to specific individual characteristics. Even without such testing, many clinical specialties use existing clinical individual level information to maximize a patient’s absolute benefit from treatment compared to its potential harms. An example of this is the use of easily accessible prognostic models for decisions about the choice of adjuvant chemotherapy in breast cancer. Those healthcare systems that use cost-effectiveness analysis to inform decisions increasingly take a step further in seeking to identify the groups of patients for whom absolute health benefit gains justify the relevant cost. Furthermore, despite being financed through taxation, social insurance or private insurance, many collectively funded jurisdictions have recognized the role for individual patient choice in healthcare decisions. There are several reasons for such a policy, and one of these is the potential role for patient choice as a vehicle for characterising unobserved heterogeneity in the costs and benefits of medical interventions.
This article reviews the key elements of the discussion about how heterogeneity should be examined, exploited and analysed for the purposes of decision-making about healthcare interventions. In terms of the methods for economic analysis, it focuses on the role of understanding heterogeneity as a source of value to achieve greater health. The remaining of the article is in four sections. The first section seeks to review standard approaches to the assessment of heterogeneity. The next explores methods developed to represent the value of considering heterogeneity in healthcare decision-making. The third describes the role of patients’ choices and preferences in understanding heterogeneity. Finally, the authors conclude by summarizing the key messages of the article highlighting the opportunities for further research.
Standard Approaches To Assess Heterogeneity In Evaluation Of Healthcare Technologies
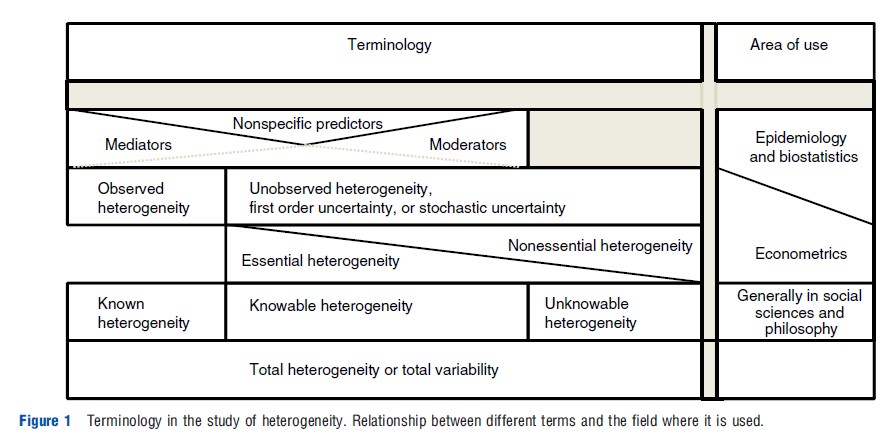
The term ‘variability’ is used to express the differences in outcomes between individuals. They can be explained by both observed and unobserved characteristics. ‘Heterogeneity’ has been defined as the proportion of the variability that can be explained by a set of observed (known) characteristics at the time of analysis. In general terms, the set of characteristics that explain the total variability can be further divided in the knowable and the unknowable. In practice, only a portion of the knowable factors can be identified and observed, mainly because of the lack of data and limits on the conduct of further research (e.g., funding and human resources). These knowable only in principle characteristics go with the other unknowable characteristics in the general category of unobserved characteristics. In this article the authors consider unobserved variability or unobserved heterogeneity synonymous. This unobserved part is also referred as stochastic uncertainty or first-order uncertainty.
‘Complete information’ refers to knowledge of the set of covariates that are able to explain differences in outcomes between all individuals in the population (total variability or total heterogeneity). This is a theoretical concept that is reached when all the covariates needed to explain differences between individuals are revealed. ‘Perfect information’ refers to the knowledge of the true mean effect of a particular covariate (and its correlation with others) on the health outcome. Likewise, perfect information also refers to the knowledge of the true value of a particular covariate in one individual (e.g., the presence of a genetic characteristic with 100% accuracy). From a decision-making point of view, the main challenge is to take into account as much information about individual level characteristics as possible. The aim for health researchers is, therefore, to achieve a full characterization of total heterogeneity, i.e., not only to convert the knowable characteristics into observed measurable variables, but also to make some prediction of the expected individual outcomes considering unobserved heterogeneity.
The literature in different areas provides alternative nomenclatures in the study of heterogeneity. For example, epidemiology and biostatistics emphasize the importance of distinguishing between moderators, mediators or nonspecific predictors of treatment outcomes. Variables considered as moderators inform for whom and under which conditions the treatment works. Mediators, in contrast, indicate potential mechanisms that explain the causal effect. Nonspecific predictors are variables that show an effect on the outcome without interacting with the treatment. These distinctions are relevant in understanding the underlying causal model of the health problem. In the context of the evaluation problem in econometrics, unobserved heterogeneity has been termed ‘nonessential heterogeneity’ when the selection of treatment does not depend on these unobserved characteristics. When treatment selection depends on the unobserved expected gains, this is called ‘essential heterogeneity’. In the context of epidemiology and biostatistics, essential heterogeneity indicates that there are knowable moderators of treatment effect that are unobserved in the data. More generally, terms such as observable or measurable heterogeneity are broadly used across the sciences. Figure 1 synthesizes these terms, making a parallel correspondence between them. For example, observable heterogeneity includes, on one side, mediators, moderators and nonspecific predictors. However, it includes known and knowable heterogeneity. Unobserved heterogeneity, also called first order uncertainty or stochastic uncertainty, includes part of the observable heterogeneity (the part that has yet to be revealed) and the unobservable (or unknowable) heterogeneity.
In clinical epidemiology and economic evaluation, exploration of heterogeneity has classically been driven by subgroup analysis. Usually, the dimensions explored correspond to baseline (or underlying) risk and treatment effect heterogeneity. Heterogeneity in baseline risk refers to the set of characteristics that predict a particular a priori probability of presenting the health outcome under standard care or without intervention (natural history). This probability may influence the effect of a new intervention relative to standard care, where the relative treatment effect might be expressed as, for example, a relative risk, odds ratio, or hazard ratio. However, even in the case where the relative treatment effect is the same across individuals, the absolute value of the health outcome can vary across patients if they are expected to have different baseline risk profiles.
Treatment effect heterogeneity, however, exists when a set of patient characteristics predict different relative treatment effects among a population of patients. In statistical terms, this corresponds to the interaction between the treatment effect and the covariate that defines the individual’s membership of a particular subgroup. Treatment effect heterogeneity can be categorized as a quantitative interaction (differences between subgroups are in the same direction but they vary in terms of their magnitude), effect concentration (the treatment effect is only seen in one subgroup) and qualitative interaction (the treatment effect varies not only in magnitude but also in direction between subgroups). It is important to stress that both baseline risk and relative treatment effect heterogeneity are defined on the basis of one or more observed characteristics at baseline, assessed on the basis of health outcome(s).
Dealing with heterogeneity in economic evaluation may also relate to costs and preferences . Heterogeneity in costs typically takes the form of a set of patient characteristics predicting differences in the use of healthcare resources. For example, age might be expected to explain a large proportion of the variation in length of hospital stay for common procedures such as hip and knee replacement and heart failure. Heterogeneity in preferences is considered in detail below.
So far the discussion has focussed on heterogeneity at the level of the individual patient. Geographical variation has also been a matter for attention, particularly in cost-effectiveness analysis. This has been explored mostly in the context of countries, although this type of heterogeneity could also be important between localities or jurisdictions within a country, with specific characteristics that affect, for example, the incidence or prevalence of a particular condition. These differences can be explained by several elements of the health system, clinicians, patients or wider socioeconomic factors. For example, the relative prices of resources may vary across jurisdictions as well as the opportunity cost imposed on health outcome through additional costs falling on the system. Similarly, it is known that teaching and specialized hospitals incur higher expenditure than general hospitals, with marked differences within the same jurisdiction. Further, better trained health professionals might generate better clinical results and incur fewer costs as a result of more efficient care (e.g., quicker diagnostics and lower complication rates in surgical procedures).
Despite the growing interest in considering heterogeneity as part of decision-making in healthcare, researchers face some constraints in using these methods due to the orthodox adherence to classical methods of statistical inference. The first of these follows from the fact that most clinical trials are designed to find statistically significant average treatment effects and their sample sizes are determined accordingly, any attempt to make inference on subsets of the sample faces the problem of loss of power (i.e., increase in type-2 error). It can be shown, however, that using prespecified (baseline) covariates in a regression framework increases statistical power, something that can be explained by the magnitude of the prognostic effect of the covariate on the outcome. A second concern relates to the fact that, when additional testing is performed on the same data, there is a higher probability of finding statistically significant differences between groups explained by chance, a problem known as multiplicity (i.e., leading to greater false positives or an increase in type-1 error).
A third problem concerns the requirement of an interaction test to prove treatment effect heterogeneity in clinical studies. If heterogeneity in a treatment effect is shown to be statistically significant, authors usually report both baseline and treatment effect heterogeneity. In contrast, if there is no statistical significance, information about (significant) baseline risk heterogeneity might be omitted. Although from a clinical point of view only treatment effect heterogeneity might be considered important, systematic variation between patients in baseline risk is also a relevant source of heterogeneity from a decision-making perspective. Indeed, between patient heterogeneity in baseline risk – even in the presence of a homogeneous relative treatment effect – yields heterogeneous absolute treatment effects, which interests policy makers because it has implications both for budget impact and equity concerns.
A further issue is that, although these tests reflect a genuine interest in achieving reliable and precise estimates of treatment effect differences in subgroups, they have been demonstrated to have low power and a high rate of false negatives. Finally, loss of balance between arms of a trial has also been raised as a concern in estimating treatment effects for subgroups.
All these concerns are relevant for clinical studies and they do not necessarily apply in a similar way to cost-effectiveness analysis. Although inference about treatment effects is mainly based on the magnitude of probability of error (errors type-1 and -2), decision rules should also consider the consequences of those errors. Thus, economic analysis in healthcare is focused on the correct characterization of uncertainty rather than inferential decision rules (e.g., taking p-value equal to .05 as a rule of thumb). However, even in the case of decisions that follow these principles, there are some constraints on the study of heterogeneity. For example, characteristics used to explain differences in (cost)-effectiveness between individuals may be constrained by equity considerations. The National Institute for Health and Clinical Excellence (NICE) for England and Wales, for instance, states that subgroup analysis based purely on differences in treatment costs is not relevant to their decisions. Furthermore, transaction costs involved in the operationalization of decisions at an individual level or in different subgroups need to be explicitly considered in the analysis.
Value Of Heterogeneity
The consideration of heterogeneity has value for the healthcare system because greater population health can be achieved from a finite budget by conditioning treatment decisions on those factors responsible for such between-patient heterogeneity. Subgroup analysis has been the most common approach to explore heterogeneity in the context of health technology assessment. Coyle et al. (2003) represented the value of considering subgroups as the incremental net benefits (INB) that can be gained from a ‘stratified’ analysis for the case where two interventions are compared. If policy makers restrict the adoption of technologies to those subgroups with positive INB, then the gain derived from making different decisions for different subgroups is the difference between the sum of the positive INB, also termed TINBS (total INB considering subgroups) and the total INB (TINB, including positive and negative INB). In other words, it is the absolute value of the sum of the INB in those subgroups where the INB is negative. Using an alternative notation, the value of stratification can be expressed as ∆STINB:
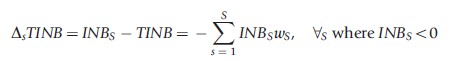
where ωsϵ(0,1) is a weight indicating the proportion of the total population represented by subgroup s and ∑SS=1ws = 1.
Basu and Meltzer (2007) developed a framework for estimating the value of eliciting information at patient level to make individualized decisions. They introduced the concept of expected value of individualized care (EVIC), a metric that reflects the population net benefits (NBs) forgone because of the ignorance of heterogeneity in preferences when decisions are made based on the average estimates. EVIC is calculated as the difference between the average of the maximum NBs in each patient (individual NBs (iNBs)) and the maximum of the average NBs of the alternative treatments across patients. This formulation of EVIC has been termed ‘with cost-internalization,’ in the sense that the decision takes into account the opportunity cost of an alternative resource allocation. According to the original definition, EVIC can be expressed as:
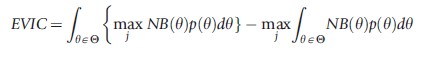
The authors point out that, although EVIC was initially estimated for patient preferences , it can also be estimated for any other (set of) parameter(s) of interest in the decision model. Indeed, a total EVIC captures all parameters of interest and should be interpreted as the expected gains that could be attained if individual information about every patient is considered when estimating the outcome of interest.
EVIC can also be expressed as ‘without cost-internalization.’ In this case, the decision at individual level follows the rule of maximising expected health benefits instead of net health benefits (i.e., without accounting for opportunity costs). In their first application of EVIC to real data, the authors demonstrate how the value of individualized information can be affected by the decision rule applied. Using an illustrative example of alternative treatments for prostate cancer, the estimated EVIC with cost-internalization was greater than US$70 million, this value fell to US$0.9 million without cost-internalization, suggesting that efforts to elicit individualized information is much more valuable if doctors (and patients) internalize costs when making their decisions. Basu and Meltzer also presented parameter-specific EVIC (EVICyi), which is analogous to the expected value of perfect information for parameters. An advantage of this metric is that by ranking parameters according to EVICyi the most valuable information for individualized decisions can be identified.
These recent methodological developments provide an adequate representation of the potential health that can be gained if heterogeneity is taken into account in decision-making. It is important to highlight that EVIC (total and for specific parameters) is conditional to the structure of and evidence within the decision model. Thus, if the model fails to capture an important source of heterogeneity, the estimate of EVIC may be unreliable. EVIC can be estimated from individual patient data or from aggregate data.
Current approaches to express the value of heterogeneity estimate the expected value of the health that could be gained by considering heterogeneity. However, sampling uncertainty must also be considered as part of the same characterization. For example, if EVIC for the parameter ‘polymorphism A’ represents the value of conducting a pharmacogenetic test to reveal whether the patient has such a polymorphism, then the estimate of EVIC implicitly assumes that the effect of having the polymorphism on the outcome is known with total precision, and also that the test is 100% accurate. Thus, EVIC provides an estimate only of the potential value of making different decision for patients with and without the polymorphism, but it does not provide any information about the probability that such alternative decisions are wrong. Consequently, an important issue that needs to be addressed is the role of decision uncertainty when heterogeneity is taken into account.
Preferences And Choice As Sources Of Heterogeneity
Preferences and choices are concepts with important implications for the study of heterogeneity across individuals.
Preferences As A Source Of Heterogeneity
Preferences have been central to how health outcomes have been valued in CEA, where the primary objective is to maximize health gain subject to a budget constraint. CEA often uses quality adjusted life years (QALYs) as a measure of health gain. Although the QALY can only be assumed to accord with individual preferences under very strong assumptions, quality of life weights are generally taken as reflecting the preferences of the relevant group of responders (typically patients or the public). Indeed, some methods used to elicit quality of life weights for QALYs have a strong basis in preferences theory (e.g., the standard gamble method is derived from expected utility theory). These methods estimate a relative value of descriptive health states, which are a representation of a particular level of health related quality of life (HRQoL).
Although heterogeneity in preferences was an important part of the development of the concept of EVIC by Basu and Meltzer, relatively few studies have addressed the idea of considering heterogeneity in patients’ preferences. Nease and Owens (1994) introduced the idea of estimating individualized expected health benefits to realize the value of a guideline that considers individual patients’ preferences . Using a decision model for mild hypertension, they showed that decisions guided on the basis of individualized preferences assessment should be considered cost-effective compared to average preferences estimates. Sculpher (1998) compared different preferences -based approaches to treatment allocation (based on expected individual health, expected individual cost-effectiveness and free treatment choice by the patient), revealing that decisions based on expected individual QALYs and net QALYs are not well correlated with treatment choice. This probably reflects the limited link between QALYs and individual preferences . In other words, patients were basing their treatment choices on criteria not reflected in the derivation of the QALY.
Choice As A Source Of Heterogeneity
An optimal (treatment) choice for an individual patient is one that maximizes the individual’s welfare, utility or health depending on the elements in his/her objective function. In the context of healthcare, ex-ante choices are the decisions that a data analyst expects the patients to make based on some of the observed patient characteristics but without access to other relevant information and points of views that patients may face while making actual decisions. This view contrasts with the notion of treatment selection (or revealed choices or ex-post choices) which is the individual’s decision resulting from the interaction of the patient with health professionals, relatives and other sources of information that are relevant for the decision, but were unobserved to the data analyst trying to predict these choices. This can be operationalized in the context of, for example, a shared decision-making model, where patients and health professionals share information about alternative diagnostic and treatment options as well as outcome preferences with the aim of making the best choice among the alternative courses of action. Expost choices can also be driven by anticipated gains and losses. To the extent that these anticipations are not completely unfounded and they deviate from the average gain and loss from a treatment, ex-ante prediction of choices can be substantially different from ex-post choices. This has implications for policy making.
A policy concern for many healthcare systems is that patients’ preferences and choices should be taken into consideration in the decision-making process. NICE, for example, recognizes this argument as part of its social value statement, but it also highlights the importance of making adequate judgments to ensure good use of the limited resources. Less clear, however, is the extent to which patients’ unconstrained treatment choices can be consistent with the social objective of maximising health gain subject to finite resources. One possibility is that patients’ choices can provide some information about the expected potential health gains from a particular treatment. In other words, choices provide information on the extent to which a patient expects (or is expected) to benefit from an intervention.
In the clinical trials literature it has been reported that when patients are allocated to their preferred treatments, their outcomes are affected positively without effect on attrition rates. This might indicate that treatment works better in patients who would choose it, irrespective of the causes that explain loss in follow-up. If ex-ante choices can be used to predict outcomes, then they could help select treatment as a form of subgroup analysis. However, findings indicating that ex-ante choices are not good predictors have also been reported. Although the role of ex-ante choices as predictors is not clear, this might not be the case for ex-post choices. Given the process needed to reveal those choices, they are likely to be more predictive of health outcomes than ex-ante choices. If so, revealed choices might correlate strongly with many other unobserved covariates that explain variability in health outcomes. Thus, by using appropriate statistical techniques, individual treatment effects could be estimated and their heterogeneity at individual level characterized, producing a better understanding of the joint distribution of potential health outcomes (potential outcomes are defined, according to the Rubin’s causality model, as the observed consequences (Y) of alternative treatments (t = 0,1) in one particular individual (i), i.e., the outcome observed de facto and the counterfactual (unobservable), which defines the joint distribution as G[Y0i,Y1i]). A research agenda for understanding heterogeneity should include new approaches to reveal individual choices and their role in explaining variability in health outcomes. This should address alternative study designs and analytical techniques.
Some governments and health systems value providing patients with (at least some) unconstrained choices over the healthcare they receive regardless of the impact on their ultimate health outcome. This principle of patient autonomy may, however, clash with an efficiency objective of maximising health across population from available resources. That is, owing to resource limitations, one patient’s choice can be another patient’s health loss. To the extent that social decision makers have a more complex objective function which includes population health and patient autonomy, then economic evaluation will need to establish how one objective is valued against the other.
Conclusions
In conclusion, heterogeneity in decision-making is occupying an important place in the health research agenda, not only because there is an intrinsic value for individualization of care but also because it is consistent with the objectives of maximizing health under limited budgets. Important conceptual and methods contributions have made in the past few years; however, there are still several gaps that require further research. Future investigation should examine the need to produce a more systematic approach to exploring heterogeneity (e.g., through subgroup analysis), the incorporation of parameter uncertainty in a more integrative framework with heterogeneity and the exploration of the role of patient choices in explaining variation in health outcomes.
Bibliography:
- Basu, A. and Meltzer, D. (2007). Value of information on preferences heterogeneity and individualized care. Medical Decision Making 27(2), 112–127.
- Coyle, D., Buxton, M. J. and O’Brien, B. J. (2003). Stratified cost-effectiveness analysis: A framework for establishing efficient limited use criteria. Health Economics 12, 421–427.
- Nease, Jr, R. F. and Owens, D. K. (1994). A method for estimating the cost- effectiveness of incorporating patient preferences into practice guidelines. Medical Decision Making 14, 382–392.
- Baron, R. M. and Kenny, D. A. (1986). The moderator-mediator variable distinction in social psychological research: Conceptual, strategic and statistical considerations. Journal of Personality and Social Psychology 51, 1173–1182.
- Basu, A. (2011). Economics of individualization in comparative effectiveness research and a basis for a patient-centered healthcare. Journal of Health Economics 30(3), 549–559.
- Briggs, A., Sculpher, M. J. and Claxton, K. (eds.) (2006). Decision modelling for health economic evaluation. Gosport, Hampshire: Oxford University Press.
- Conti, R., Veenstra, D. L., Armstrong, K., Lesko, L. J. and Grosse, S. D. (2010). Personalized medicine and genomics: Challenges and opportunities in assessing effectiveness, cost-effectiveness, and future research priorities. Medical Decision-making 30, 328–340.
- Hamburg, M. and Collins, F. (2010). The path to personalized medicine. New England Journal of Medicine 363, 301–304.
- Heckman, J. J., Clements, N. and Smith, J. (1997). Making the most out of programme evaluations and social experiments: Accounting for heterogeneity in program impacts. Review of Economic Studies 64, 487–535.
- Heckman, J. J., Urzua, S. and Vytlacil, E. J. (2006). Understanding instrumental variables in models with essential heterogeneity. Review of Economics and Statistics 88, 389–432.
- Kravitz, R., Duan, N. and Braslow, J. (2004). Evidence-based medicine, heterogeneity of treatment effects, and the trouble with averages. Milbank Q 82, 661–687.
- Manca, A., Rice, N., Sculpher, M. J. and Briggs, A. H. (2005). Assessing generalisability by location in trial-based cost-effectiveness analysis: The use of multilevel models. Health Economics 14, 471–485.
- National Institute for Health and Clinical Excellence. (2005). Social value judgments: Principles for the development of NICE guidelines, 2nd ed. London: NICE. Available at: www.nice.org.uk (accessed 30.05.12).
- National Institute for Health and Clinical Excellence. (2008). Guide to the Methods of Technology Appraisal. Available at: www.nice.org.uk (accessed 30.05.12).
- Nease, R. F., Kneeland, T., O’Connor, G. T., et al. (1995). Variation in patient utilities for outcomes of the management of chronic stable angina. Journal of the American Medical Association 273, 1185–1190.
- Oxman, A. and Guyatt, G. (1992). A consumer’s guide to subgroup analyses. Annals of Internal Medicine 116, 78–84.
- Sculpher, M. J. (2008). Subgroups and heterogeneity in cost-effectiveness analysis. Pharmacoeconomics 26, 799–806.
- Sculpher, M., Pang, F., Manca, A., et al. (2004). Generalisability in economic evaluation studies in healthcare: A review and case studies. Health Technology Assessment 8, 49.
- Stinnett, A. A. and Mullahy, J. (1998). Net health benefits: A new framework for the analysis of uncertainty in cost-effectiveness analysis. Medical Decision-making 18, S68–S80.