A multiattribute utility (MAU) instrument consists of (1) a health questionnaire that establishes a health profile and (2) a scoring system that converts the multiattribute profile into an overall utility score. A generic MAU instrument can be used for all patients, whereas a condition-specific MAU instrument is intended only for patients with the condition of interest. Overall utility scores are used in economic evaluation of health care in terms of cost-utility analyses, where benefits are measured using quality-adjusted life-years (QALYs). They can also be used in monitoring of population health in terms of quality-adjusted life expectancy (QALE).
Some reimbursement agencies prefer the use of generic MAU instruments to generate QALYs. However, the generic measures may not always be available or appropriate. There is published evidence indicating that existing generic MAU instruments are valid, responsive, and reliable for many conditions. However, generic MAU instruments have been shown to perform poorly in terms of validity or responsiveness to change in some conditions. For example, the generic EQ-5D has been found to perform poorly in visual impairment in macular degeneration, hearing loss, leg ulcers, and schizophrenia. For these conditions the descriptive system of the generic MAU instruments either does not capture the impact of the change for that condition within its dimensions, or is not sufficiently able to capture small changes within a dimension. This means that the generic MAU instruments will not capture potentially important changes in utility across interventions because of the inadequacy of the descriptive system for that patient group. Condition-specific multiattribute utility instruments by contrast are designed to focus on functionings and symptoms that are affected both by the condition and treatments for the condition. This enables them to capture potentially important changes better across interventions for that condition.
In the following greater details on the construction and use of condition-specific MAU instruments are provided. Section ‘Construction’ summarizes their construction. Section ‘Validity’ examines their performance both in comparison to condition-specific instruments that are not preference-based and generic MAU instruments and addresses some further issues regarding validity. Section ‘Future developments’ outlines future developments. Additional readings are provided which contain information and References: supporting the text in this article.
Construction
Background
Condition-specific measures vary in composition but typically have multiple domains, at least some of which may be highly correlated and not independent, and each of which has multiple items. The number of domains and items is often large (e.g., 30 items). The scoring process is often not based on preference (i.e., non-preference-based), as item scores are typically summed to obtain a domain score and an overall score across all items. This simple summative scoring unrealistically assumes that all items, and the difference between all response choices, are equally important. Changes in scores do not necessarily reflect changes in quality of life that are valued by either patients or the general population. In the following these non-preference-based condition-specific measures are referred to as ‘NPCS measures.’
Clinical studies often use NPCS measures (e.g., the cancerspecific EORTC QLQ-C30) and do not include generic MAU instruments. This is in part because of concerns about the appropriateness of generic measures in some conditions, but is also because of concerns surrounding patient burden and costs. Many trials are designed to provide information for multiple analyses (e.g., licensing and labeling claims) rather than economic evaluation alone, and often NPCS measures are used in these analyses rather than generic MAU instruments. This means that NPCS measures will continue to be an important source of evidence for economic evaluation. However, these measures cannot be used directly to generate QALYs. As shown by John Brazier and colleagues, they can be used indirectly to generate QALYs using mapping, which uses the statistical relationship between the NPCS measure and a MAU instrument to estimate utility scores using data from the NPCS measure alone. However, NPCS measures can be used directly if a condition-specific MAU instrument is derived from them. Section ‘Development from existing non-preference-based condition-specific measure’ describes this process.
Development From Existing Non-Preference-Based Condition-Specific Measure
For the majority of condition-specific MAU instruments the scoring system generates a score using responses to only a subset of the items included in the questionnaire. This is because the original questionnaire was often not designed as a MAU instrument and typically contains a large number of items across many domains. To derive utility scores from the questionnaire a subset of items is selected to form a descriptive system, which contains a small number of dimensions and severity levels for each dimension. The descriptive system is used to describe all possible health states with its associated utility score. What this means in practice is that for conditionspecific MAU instruments the utility scores are usually generated by converting data for an existing questionnaire in the same way that SF-36 or SF-12 data are used to generate the SF- 6D. For example, the cancer-specific EORTC QLQ-C30 data are used to generate the EORTC-8D cancer-specific utility score. This has the advantage that many condition-specific utility scores can be generated using existing data sets. Furthermore these data sets will contain both domain scores for the original instrument and a utility score to provide detailed information for a range of analyses.
Figure 1 reports a six-stage process for deriving a condition-specific MAU instrument from an existing non-preference-based condition-specific measure that was first used to derive an overactive bladder-specific MAU instrument (AQL- 5D) from the overactive bladder questionnaire (OABq). Stages 1 to 4 produce the descriptive system and stages 5 and 6 generate utility scores for all states defined by the descriptive system.
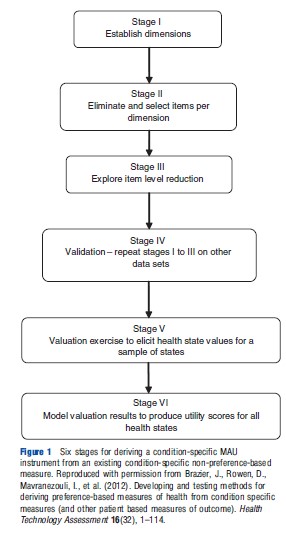
Stages 1 to 3 produce the descriptive system using existing data for the NPCS measure, and stage 4 validates the descriptive system using other data. Stages 1 to 3 provide the structure of the descriptive system by selecting dimensions and a minimum number of items per dimension to fully represent that dimension. This involves the use of psychometric techniques such as factor analysis, Rasch analysis, and Item Response Theory alongside classical psychometric techniques such as standardized response means and effect sizes. This process is undertaken to ensure that the selected descriptive system accurately represents the dimensionality and maintains the desirable psychometric properties of the original instrument. For example, the overactive bladder questionnaire has 33 items each with 6 severity levels covering 5 domains: symptom bother; sleep; coping; concern; and social interaction. The descriptive system of the OAB-5D MAU instrument derived from the questionnaire has 5 dimensions: urge to urinate; urine loss; sleep; coping; and concern each with 5 severity levels (Young et al., 2009).
Stage 5 elicits health state utility scores for a sample of health states. Even health state descriptive systems like OAB- 5D define thousands of health states meaning it is impractical and infeasible to value all states. A sample of health states are selected for valuation using a variety of techniques such as an orthogonal array or balanced design. The selection process differs by whether multiattribute utility theory (MAUT) or statistical inference is the proposed modeling strategy for stage 6 and the valuation technique used, but states are selected in order to enable utility scores for all states to be estimated from the elicited data for the sampled states. A variety of elicitation techniques is used, such as time trade-off (TTO), standard gamble (SG), visual analogue scale (VAS), and discrete choice experiment (DCE). Preference can be elicited from a variety of sources including general population, patients, and carers. However, it should be noted that when patients value health states in such experiments they value hypothetical health states, not their own health state, to enable these values to be used to estimate scores for all health states described by the descriptive system. Currently, general population preference are typically recommended by health economists if the measure will be used in economic evaluation submitted to policy decision makers. However, as noted by Mike Drummond and colleagues, this is being debated. Stage 6 models the utility data to produce utilities for every health state defined by the descriptive system. The modeling follows either a MAUT or statistical inference approach and will differ depending on the process used to select states and the elicitation technique. As noted by John Brazier and colleagues, the process will also differ if the instrument is not multiattribute with multiple independent attributes, but instead has one main attribute, such as flushing or mental health.
New Developments
The descriptive systems for some condition-specific MAU instruments are developed ‘de novo’ rather than derived from existing non-preference-based condition-specific measures, requiring a modified approach for stages 1 to 4 outlined above. The most rigorous method of development of a new descriptive system involves qualitative research to identify dimensions and items and validation of the generated descriptive system using psychometric analyses before valuation. Other approaches in the literature include the use of psychometric analyses on a battery of existing measures or a literature review. Recent US Food and Drug Administration (FDA) guidance for industry (U.S. Department of Health and Human Services Food and Drug Administration (FDA), 2009) outlines guidelines for the development of dimensions and items for non-preference-based measures and emphasize the role of patients with the condition in generating and validating the content. Valuation follows the process as outlined in stages 5 and 6 above.
Description Of Existing Instruments
Table 1 outlines the descriptive systems for existing conditionspecific MAU instruments. Instruments were identified by John Brazier and colleagues in a recent review of published studies. Unpublished instruments that the authors were aware of were added to the list (see http://www.sheffield.ac.uk/scharr/sections/ heds/mvh). There are 28 instruments covering 27 different conditions ranging from exact diagnoses, such as glaucoma and lung cancer, to more general conditions, such as visual impairment and cancer. The size of the descriptive system varies greatly by measure, with a range of possible health states for a system ranging from 10 to 390 625. The focus of the dimensions differs across instruments: (1) symptoms or health-related quality of life (HRQL) and (2) condition-specific dimensions alone or dimensions able to capture side effects and comorbidities. Indeed, dimensions vary for instruments within a condition or International Classification of Diseases.
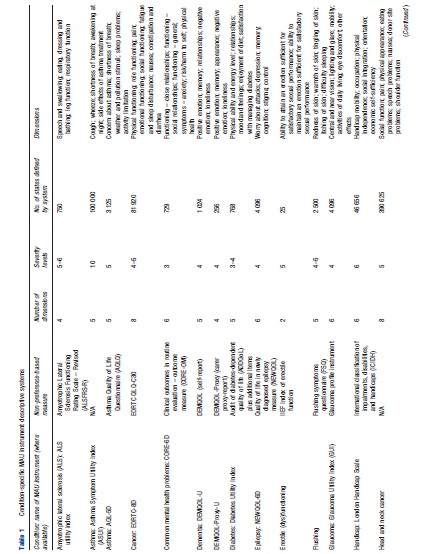
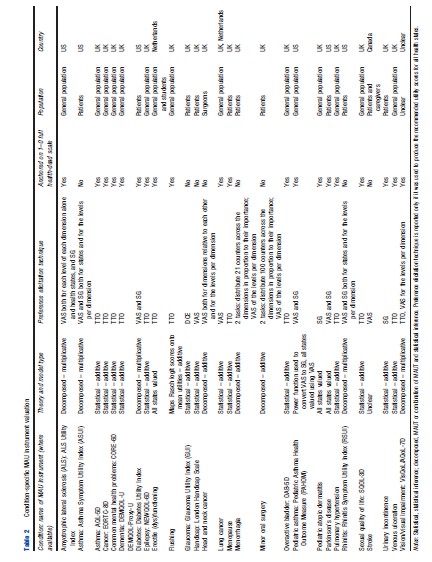
Table 2 outlines the valuation processes used to produce utility scores for all states defined by the descriptive system of the various condition-specific instruments. Fourteen instruments use the statistical inference approach to select health states for valuation and model utilities, and eight instruments use a decomposed approach, which is either a pure MAUT approach or an approach combining statistical inference and MAUT. Three instruments value all health states defined by the descriptive system and thus require no modeling to produce utility scores for all health states. TTO, VAS, and SG and combinations of these were most commonly used to elicit utility scores. Twelve instruments have values elicited using TTO, six used VAS and SG, four used VAS alone, two used SG alone. Although VAS was used in 13 instruments and is the most commonly used technique, its usage differs across studies varying from valuing health states to valuing severity levels within a dimension or valuing different dimensions. Eight instruments cannot be used to estimate QALYs as they are not anchored onto the full health-dead 1–0 scale required to estimate QALYs. Half of the measures are valued using only a general population sample, with 10 measures valued by patients and one by patients and carers (using hypothetical states not own state). Valuation studies across all instruments have only been conducted in the UK, the US, Netherlands, and Canada with the majority of instruments valued only in the UK.
Validity
Comparison Of Performance To Original Measure
There is little published analysis examining the extent of information loss arising from moving from the original non-preference-based condition-specific measure to a smaller condition-specific MAU instrument. However, evidence reviewed recently by John Brazier and colleagues suggests that there is either no information loss or a minimal degree of information loss when examining patient data sets for instruments produced for asthma, cancer, common mental health problems, and overactive bladder in terms of discrimination across severity group and responsiveness to change over time. This is reassuring given the rationale for deriving a MAU instrument from an existing measure is to benefit from its relevance and sensitivity, and means that this informational advantage is retained in the process of deriving a MAU instrument from the original measure.
Comparison Of Performance To Generic MAU Instruments
Overall there is limited evidence comparing the performance of condition-specific and generic MAU instruments and it is mainly concerned with psychometric tests such as known group differences and responsiveness. However, analyses comparing generic EQ-5D to instruments produced for asthma, cancer, and common mental health problems found that the condition-specific MAU instruments performed better than EQ-5D regarding discriminative validity across severity groups. Figure 2 plots pair-wise comparisons of EQ-5D and these condition-specific MAU instruments, demonstrating that the condition-specific MAU instruments have a narrower range of utility scores than EQ-5D but there is a large dispersion of condition-specific MAU scores for each EQ-5D score (and vice versa). Unlike EQ-5D the condition-specific MAU instruments did not suffer from ceiling effects (where a large proportion of respondents report themselves as in full health and are clustered at the top end of the scale), suggesting they are more responsive for patients at the upper end of HRQL. It is also clear that there are differences between the condition-specific MAU instruments and EQ-5D at the observational level, and the condition-specific utility scores are typically higher with the exception of observations in full health on EQ-5D. Although research found that the condition-specific MAU instruments were better at discriminating between groups with different severity, they were comparable to EQ-5D regarding responsiveness to change following treatment (although for responsiveness this is based on little data owing to limited data availability). Typically, mean change over time and differences between severity groups were smaller for the condition-specific MAU instruments but with smaller standard deviation that improved precision in comparison to EQ-5D. This reduced uncertainty in utility scores for different time periods and severity groups is important for trials. However, the smaller mean change over time or across groups found using these condition-specific MAU instruments may potentially indicate that interventions are less cost–effective. Further research is needed to determine whether these findings are generalizable to all condition-specific MAU instruments. It should be noted that as a MAU instrument contains a subset of items from the original measure it will only offer an improvement on a generic MAU instrument if the original non-preference-based condition-specific measure offers an improvement. Therefore, the development of conditionspecific MAU instruments from existing measures should be limited to measures already shown to be more responsive and valid.
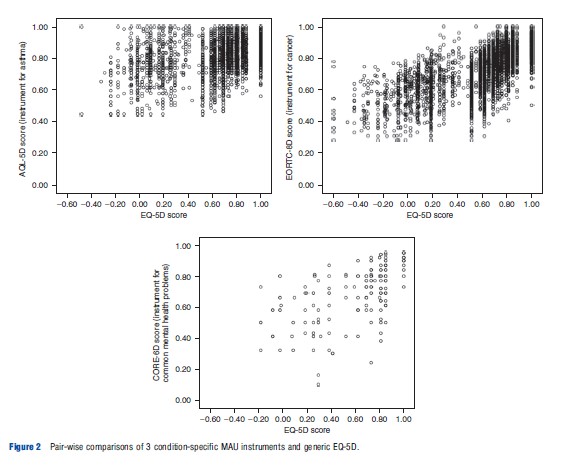
Table 1 Condition-specific MAU instrument descriptive systems
Table 1.1 Continued
Table 2 Condition-specific MAU instrument valuation
Other Issues
Condition-specific MAU instruments have been criticized on the grounds of focusing effects. It has been argued that respondents may provide lower utility scores for health states with only condition-specific dimensions as they are focusing on the problems presented rather than judging these relative to other generic dimensions of health that are not impaired, such as mobility or self-care. But this is not supported by evidence of the kind shown in Figure 2.
Some evidence suggests that the inclusion of the condition label in the health state descriptions used to elicit utility scores can itself affect results (e.g., a ‘cancer’ label was found to lower values). The inclusion of these condition labels is often unavoidable as the condition is embedded into the descriptive system (e.g., take the dimension ‘concern about asthma’) and is an important factor that may affect health state utility scores for condition-specific MAU instruments and question comparability to values produced by generic MAU instruments.
It has been argued that condition-specific MAU instruments are unable to capture comorbidities or side effects because of their focus on the condition. Table 1 indicates that whereas this may be a concern for some instruments with a descriptive system largely focused on symptoms related to the condition, this is unlikely to be an important concern for many instruments that cover a broad range of functionings (e.g., the EORTC-8D for cancer).
In relation to focusing effects and the inability to capture side effects and comorbidities, there is a concern that elicited utility scores may be affected if the descriptive system does not contain all important dimensions. There is some evidence supporting this concern, where it was found that adding a generic dimension to an existing condition-specific MAU instrument affected the utility scores for the condition-specific dimensions. This suggests that condition-specific MAU instruments should contain all important dimensions for that condition.
Future Developments
Ongoing research will identify where generic MAU instruments are insufficient or inappropriate and condition-specific MAU instruments are appropriate. Further research examining the impact of using either generic or condition-specific MAU instruments in economic evaluation is encouraged. Future research should also examine the role of the descriptive system in valuation studies as this has largely been ignored to date. This research would determine the importance of focusing effects, condition labeling, and missing dimensions. These findings would indicate the comparability of valuation studies undertaken for generic and condition-specific MAU instruments and the accuracy of health state utility scores for condition-specific MAU instruments.
References:
- S. Department of Health and Human Services Food and Drug Administration (FDA) (2009). Guidance for industry: Patient-reported outcome measures: Use in medical product development to support labeling claims. MD: FDA.
- Young, T., Yang, Y., Brazier, J. E., Tsuchiya, A. and Coyne, K. (2009). The first stage of developing preference-based measures: Constructing a health-state classification using Rasch analysis. Quality of Life Research 18, 253–265.
- Brazier, J. E., Ratcliffe, J., Tsuchiya, A. and Solomon, J. (2007). Measuring and valuing health for economic evaluation. Oxford: Oxford University Press.
- Brazier, J., Rowen, D., Mavranezouli, I., et al. (2012). Developing and testing methods for deriving preference-based measures of health from condition specific measures (and other patient based measures of outcome). Health Technology Assessment 16(32), 1–114.
- Brazier, J., Yang, Y., Tsuchiya, A. and Rowen, D. (2010). A review of studies mapping (or cross walking) from non-preference based measures of health to generic preference-based measures. European Journal of Health Economics 11, 215–225.
- Drummond, M., Brixner, D., Gold, M., et al. (2009). Toward a consensus on the QALY. Value in Health 12(Supplement 1), S31–S35.
- Revicki, D. A., Leidy, N. K., Brennan-Diemer, F., Thompson, C. and Togias, A. (1998). Development and preliminary validation of the multiattribute Rhinitis Symptom Utility Index. Quality of Life Research 7, 693–702.
- Yang, Y., Brazier, J., Tsuchiya, A. and Coyne, K. (2009). Estimating a preference- based single index from the overactive bladder questionnaire. Value in Health 12, 159–166.